
Docker/K8s & Linux Netfilter's conntrack Nightmare
Recently I happen to deeply learn & investigate about Linux kernels Netfilter modules connection tracking limits and how it can impact the performance of any application running inside a Container.
What is Netfilter conntrack ?
Netfilter is a firewall subsystem which is part of the Linux network stack which is commanly managed by a cli called iptables. In early days Netfilter was implemented as a stateless but quickly became insufficient, so Netfilter implemented a statefull firewall which keeps record of all the connections.
This can be easily viewed
sudo conntrack -L
tcp 6 1 TIME_WAIT src=150.136.89.255 dst=192.168.2.2 sport=55824 dport=22 src=192.168.2.2 dst=150.136.89.255 sport=22 dport=55824 [ASSURED] use=1
udp 17 13 src=127.0.0.1 dst=127.0.0.53 sport=59443 dport=53 [UNREPLIED] src=127.0.0.53 dst=127.0.0.1 sport=53 dport=59443 use=1
tcp 6 431999 ESTABLISHED src=192.168.2.30 dst=192.168.2.2 sport=61167 dport=22 src=192.168.2.2 dst=192.168.2.30 sport=22 dport=61167 [ASSURED] use=1
udp 17 14 src=192.168.2.2 dst=192.73.248.83 sport=41641 dport=3478 src=192.73.248.83 dst=192.168.2.2 sport=3478 dport=41641 use=1
udp 17 13 src=192.168.2.2 dst=102.67.165.90 sport=41641 dport=3478 src=102.67.165.90 dst=192.168.2.2 sport=3478 dport=41641 use=1
udp 17 13 src=127.0.0.1 dst=127.0.0.53 sport=35164 dport=53 [UNREPLIED] src=127.0.0.53 dst=127.0.0.1 sport=53 dport=35164 use=1
udp 17 13 src=127.0.0.1 dst=127.0.0.53 sport=41767 dport=53 [UNREPLIED] src=127.0.0.53 dst=127.0.0.1 sport=53 dport=41767 use=1
.
truncate for readabilty
What is the role of Netfilter in the Container World ?
We know that containers are nothing but simple processes/code running in an isolated environment inside the Linux Operating System.
Netfilter provide network isolation for the Docker containers.
How can Netfilter impact containerized applications performance ?
Netfilter has a lot of configurations which can be refered here.
For this post let’s only focus just on one very important configuration nf_conntrack_max.
nf_conntrack_max : Size of connection tracking table. Default value depends on available memory, but what I have observed is it varies based on the distribution. eg: On a ubuntu system defaults is 65536, some other distribution or cloud provider have different defaults.
For this article let’s go with Ubuntu’s default 65536
What this means is our application container hosted(running) on this machine/vm can make maximum 65536 connections in/out.
To simplify let’s say you have just one container running on a single VM.
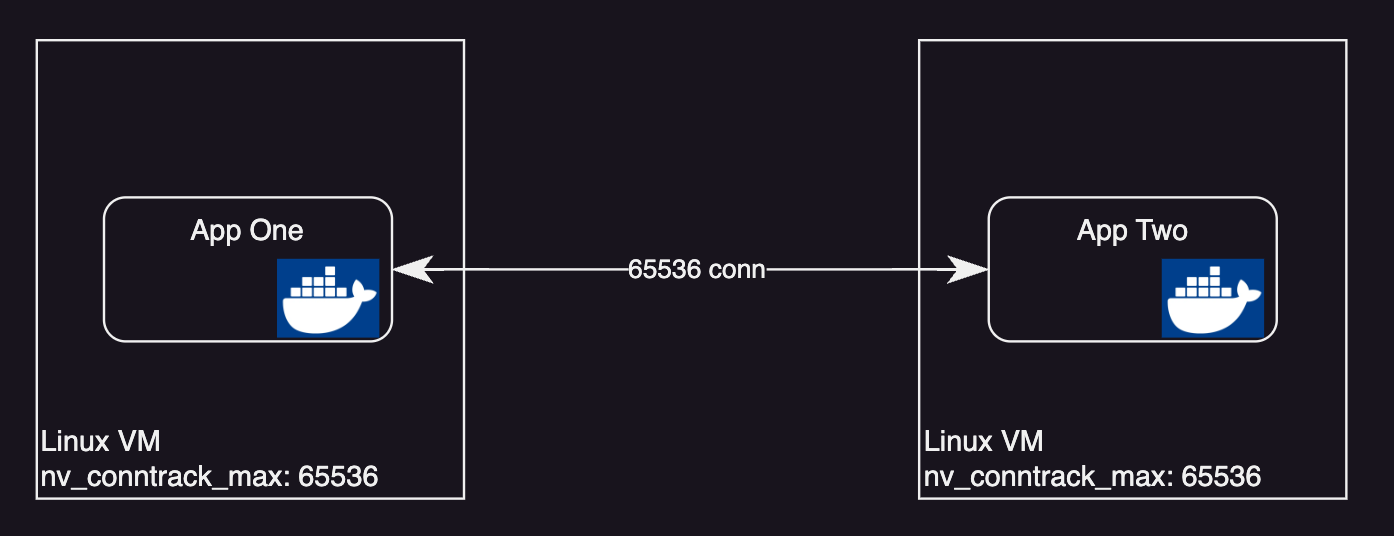
We might not see the problem yet on this because we might hit the CPU limit before we even consume all the network connections. Also in production with autoscaling kicking in you will have more VMs running your container.
Let’s take a better example, consider this deployment model.
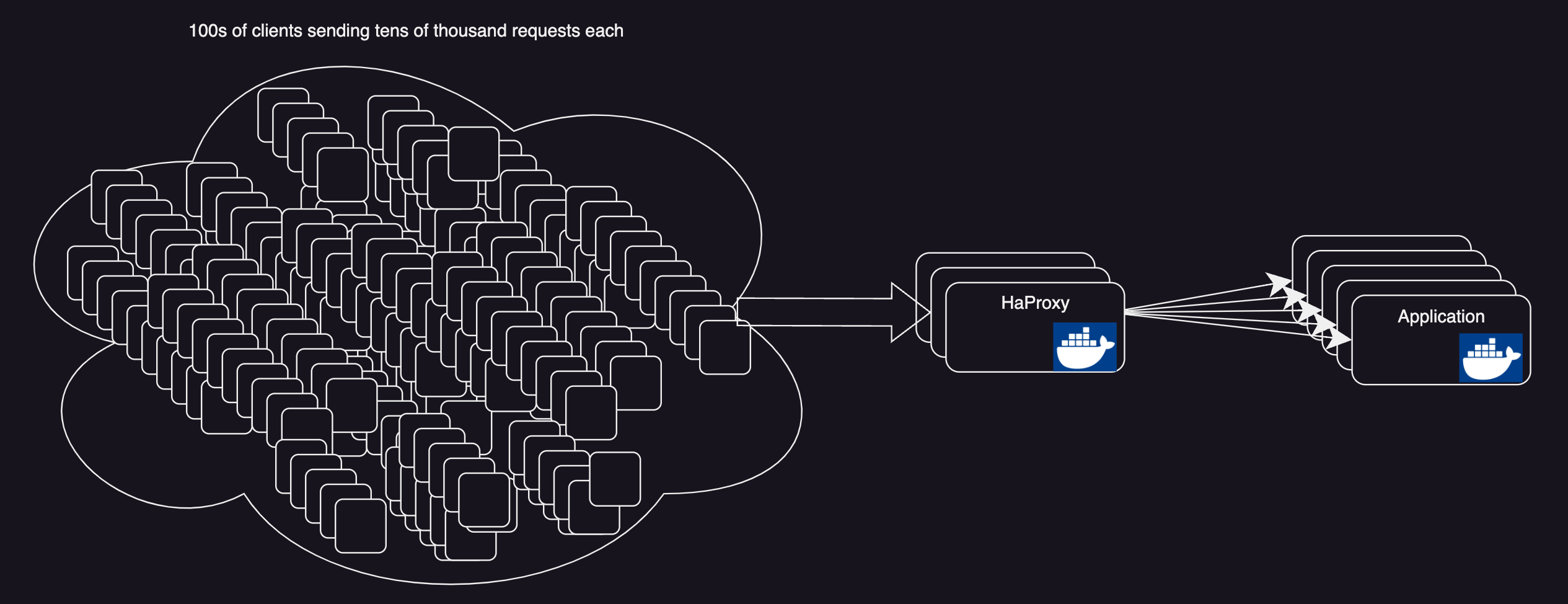
In this architecture let’s still keep the assumption that all the components are autoscaled.
But if you look carefully the
Haproxy Layerwill soon become abottle neckwith growing traffic, especially when you havemillions of requestspoiring in.Once this limit is reached server simply drops the imcoming connections.
How to detect ?
Linux kernels dmesg to the rescue. You will see the kernel logs flooded with
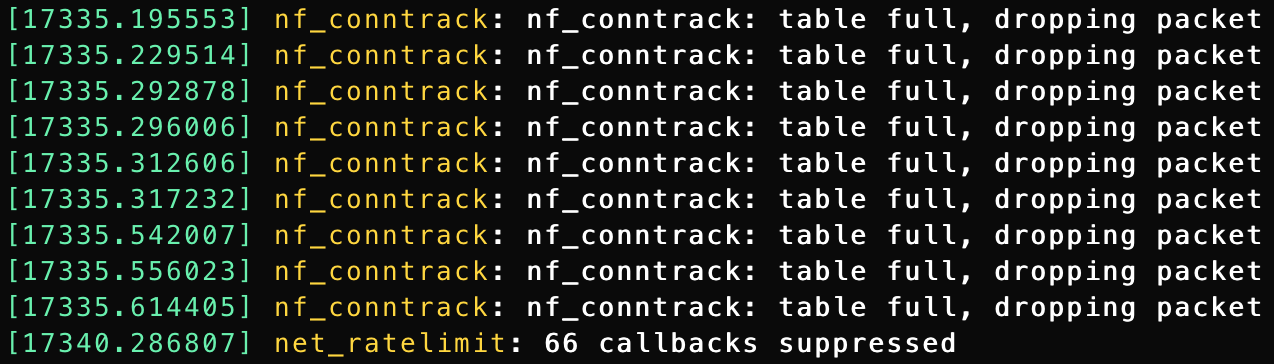
table full, dropping packetmessages.sudo dmesg -T [Thu May 11 12:38:28 2023] net_ratelimit: 59 callbacks suppressed [Thu May 11 12:38:28 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:28 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:28 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:28 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:28 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:28 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:28 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:28 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:28 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:28 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:33 2023] net_ratelimit: 66 callbacks suppressed [Thu May 11 12:38:33 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:33 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:33 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:33 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:33 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:33 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:33 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:33 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:33 2023] nf_conntrack: nf_conntrack: table full, dropping packet [Thu May 11 12:38:34 2023] nf_conntrack: nf_conntrack: table full, dropping packetThe Fix ?
Haproxy here is just acting as a Layer 4⁄7 LoadBalancer which will have a very low CPU/Mem resource usage and will not be scaled very often and pretty soon the connections will reach the default Netfilter Connection tracking limit.
Fix 1 (The costly fix)
Alright why don’t we scale haproxy based on total conenctions ? then we will be burning more $$$$$ while we have a very simple solution to this very problem.
Fix 2 (A better fix)
Just increase the connection tracking limits, but also keep your system/container memory in the calculation. In my experience I have seen we can easily bump up to 600000 on a VM with just 1GB memory and not have any side effects.
eg:
echo 600000 > /proc/sys/net/netfilter/nf_conntrack_maxTo make it persist on system reboot,
bash
Maximum number of allowed connection tracking entries
net.netfilter.nf_conntrack_max = 600000 ```
